多項式フィッティング
多項式フィッティングの問題点その2
引き続き多項式フィッティングの問題点について考えていきます。
予測精度はデータ数が沢山ないと上がらないと言われています。
ここまでデータ数は30個で検討してきました。
今度は、データ数が3倍くらいあれば精度が上がるか検討します。
Excel ファイル準備
データ数が95個ある Excel ファイル準備しました。
CHART-190325-0802.xlsx
をクリックすると PC にエクセルがインスト-ルされていれば
xlsx ファイルを開くことができるはずです。
通常ボップアップが開くのですが開かなければ、今開いている画面の一番下を見てください。
エクセルファイルが顔を出しているはずです。
又、右クリックして、このファイル名を
CHART-190325-0802.xlsx
とし、
C:\ユ-ザ-\ユ-ザ名\panda\file
フォルダをあらかじめ作成しておき、ここに、保存します。
polyfit ファイル実行結果
今回の多項式フィッティングファイル polyfit-3 の内容の変更点は
エクセルファイル名と
④の赤丸のところを4
z = np.polyfit(Idx, Close, 4) #④
とした部分の2ヶ所です。
実行結果は次のようになります。
うまくフィッティングできています。
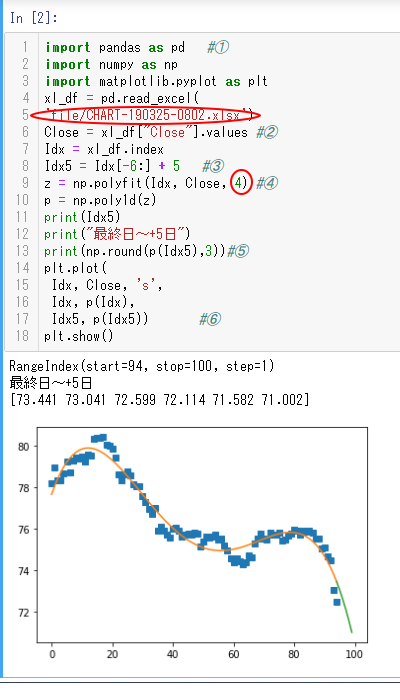
ここで、polyfitー3 ファイル実行結果の実績値■の形をざっくり見ると、
極大値が2個、極小値が1個
とみることができますので、次数 N は 4 としています。
polyfit-3 フィッティング結果
今回は将来の値をうまく予測することはできたのでしょうか?
検証してみましょう。
絶対値
Idx 日付 予測値 実績 差分
94 8/2 73.441 72.459
---- ここから予測開始 ------
95 8/5 73.041 71.630 1.4
96 8/6 72.599 71.948 0.6
97 8/7 72.114 71.823 0.3
98 8/8 71.582 72.146 0.6
99 8/9 71.002 71.665 0.7
差分絶対値合計 3.6
となり、データ数30個の時の
差分絶対値合計 3.1
に比べ改善できているとは言えません。
結局のところデータの数は多ければ多いほどよいのでしょうが、
予測したい日数の十倍ぐらいあれば十分なようです。
polyfit-4 フィッティング結果答合せ
引き続き、実績値をローソク足にしてその上にフィッティング値と予測値を表示していきたいと思います。
2019/3/25~8/2日の95個のデータ
CHART-190325-0802.xlsx
から予測し、その答えは
CHART-190325-0802-0809.xlsx
のなかの 2019/8/5~8/9日の実績値と比較しています。
それでは polyfit-4 フィッティング結果答合せファイルを作成していきます。
polyfit-4 ファイルは以下の通りです。
ここまで説明してきたことの復習です。
わからない部分がある時はその部分の番号をクリックして下さい。
詳細説明参考箇所に飛んで行きます。
#①f, #①a
#②f, #③f, #④f, #⑤f
#②a
#③a, #④a, #⑤a, #⑥a, #⑦a, #⑧a
import pandas as pd #①f
import numpy as np
import matplotlib.pyplot as plt
xl_df = pd.read_excel(
'file/CHART-190325-0802.xlsx')
Close = xl_df["Close"].values #②f
Idx = xl_df.index
# Idx は 0 スタ-ト
Idx5 = Idx[-5:] + 5 #③f
z = np.polyfit(Idx, Close, 4) #④f
p = np.poly1d(z)
print("予測値=最終日+1~+5日")
print(np.round(p(Idx5),3)) #⑤f
#ここから答合せ
from mpl_finance import candlestick_ohlc
xl_dfa = pd.read_excel(
'file/CHART-190325-0802-0809.xlsx')
Opena = xl_dfa["Open"].values #①a
Higha = xl_dfa["High"].values
Lowa = xl_dfa["Low"].values
Closea = xl_dfa["Close"].values
Datea = xl_dfa["Date"].values
Idxa = xl_dfa.index
xDate = [] #②a
xD = []
for i, key in enumerate(Datea):
if(i % 10 == 0):
e4 = str(key)[4:10]
e6 = e4.replace("-0", "/")
e7 = e6.replace("-", "/")
e8 = e7.lstrip("/")
xDate.append(e8)
xD.append(i)
ohlc = zip(
Idxa, Opena, Higha, Lowa, Closea)
fig = plt.figure(
figsize=(8.34, 5.56)) #③a
ax = fig.add_subplot(1,1,1) #④a
ax.grid()
plt.plot(
Idx, p(Idx),
Idx5, p(Idx5),'bo')
candlestick_ohlc(
ax, ohlc, width=0.5, alpha = 1,
colorup='r', colordown='g') #⑤a
plt.xticks(xD, xDate) #⑥a
plt.title('AUS$ / JPY chart')#⑦a
plt.xlabel('Date')
plt.ylabel('Yen')
plt.savefig(
'file/cand_poly.png') #⑧a
ファイルを見るとフィッティング部分はわずかで、 チャートを作るのに多くの労力を費やしていることがわかります。
polyfit-4 実行結果
polyfit-4 を実行するとまずは、
#⑤f の部分(5日間の予測値)
が表示され、次のようになります。
予測値=最終日+1~+5日
[73.041 72.599 72.114 71.582 71.002]
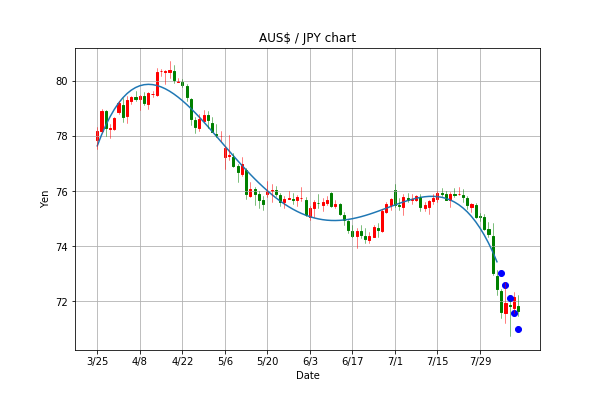
チャート図は上のようになり、青●が予測部分であり実績値に近いことがわかります。
これで多項式フィッティングに関する説明は終わりです。
polyfit ファイル実行結果 に戻る
polyfit ファイル作成準備その2 に戻る
Python 多項式フィッティング概要 に戻る